BibTeX
@article {Kim2025.02.28.25323115,
author = {Kim, Yubin and Jeong, Hyewon and Chen, Shen and Li, Shuyue Stella and Lu, Mingyu and Alhamoud, Kumail and Mun, Jimin and Grau, Cristina and Jung, Minseok and Gameiro, Rodrigo R and Fan, Lizhou and Park, Eugene and Lin, Tristan and Yoon, Joonsik and Yoon, Wonjin and Sap, Maarten and Tsvetkov, Yulia and Liang, Paul Pu and Xu, Xuhai and Liu, Xin and McDuff, Daniel and Lee, Hyeonhoon and Park, Hae Won and Tulebaev, Samir R and Breazeal, Cynthia},
title = {Medical Hallucination in Foundation Models and Their Impact on Healthcare},
elocation-id = {2025.02.28.25323115},
year = {2025},
doi = {10.1101/2025.02.28.25323115},
publisher = {Cold Spring Harbor Laboratory Press},
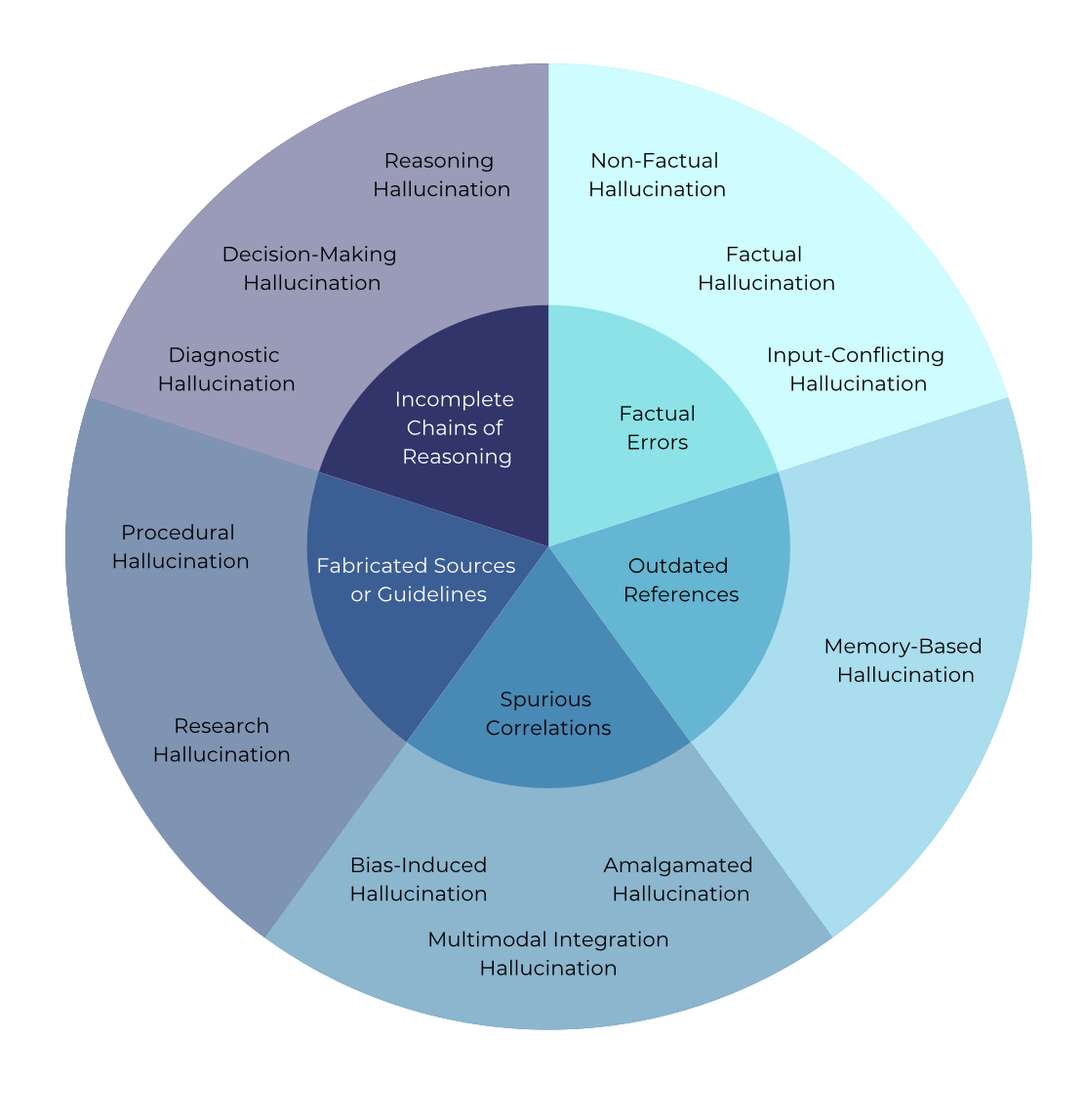
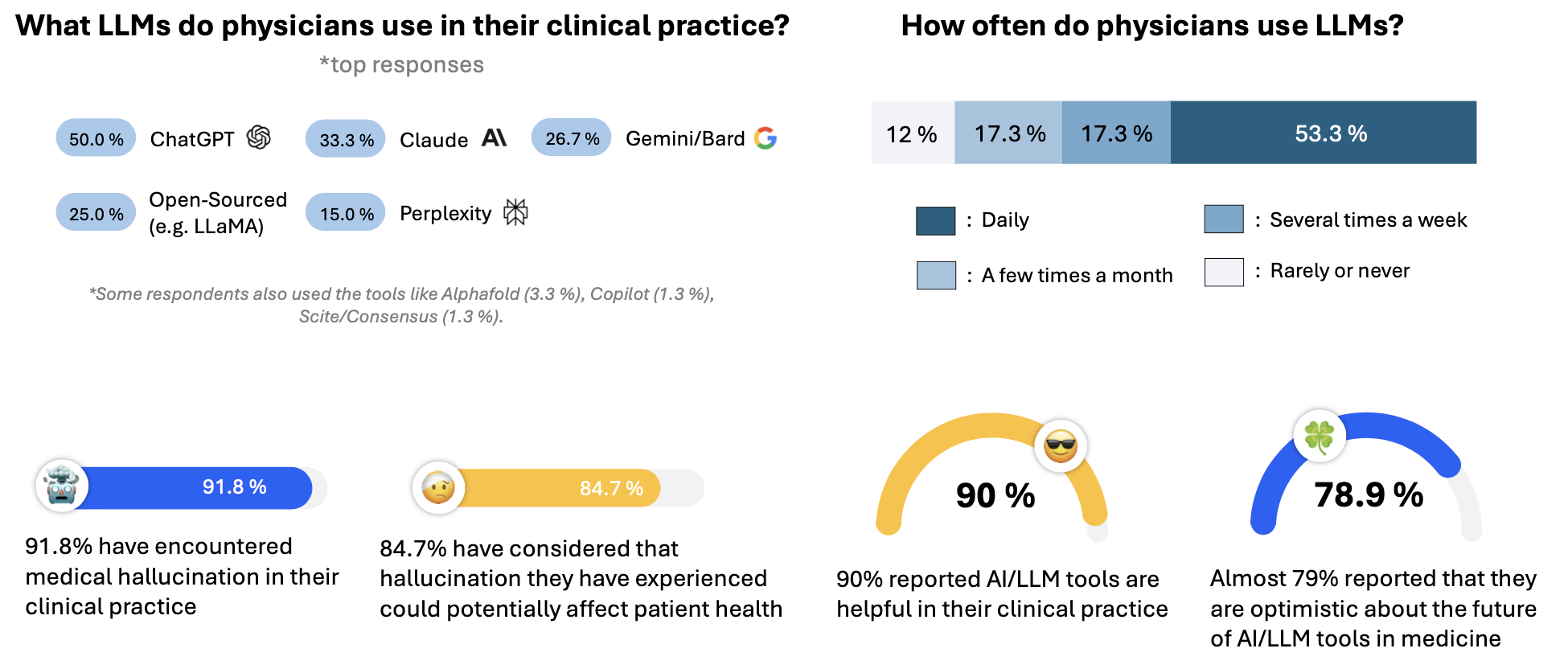
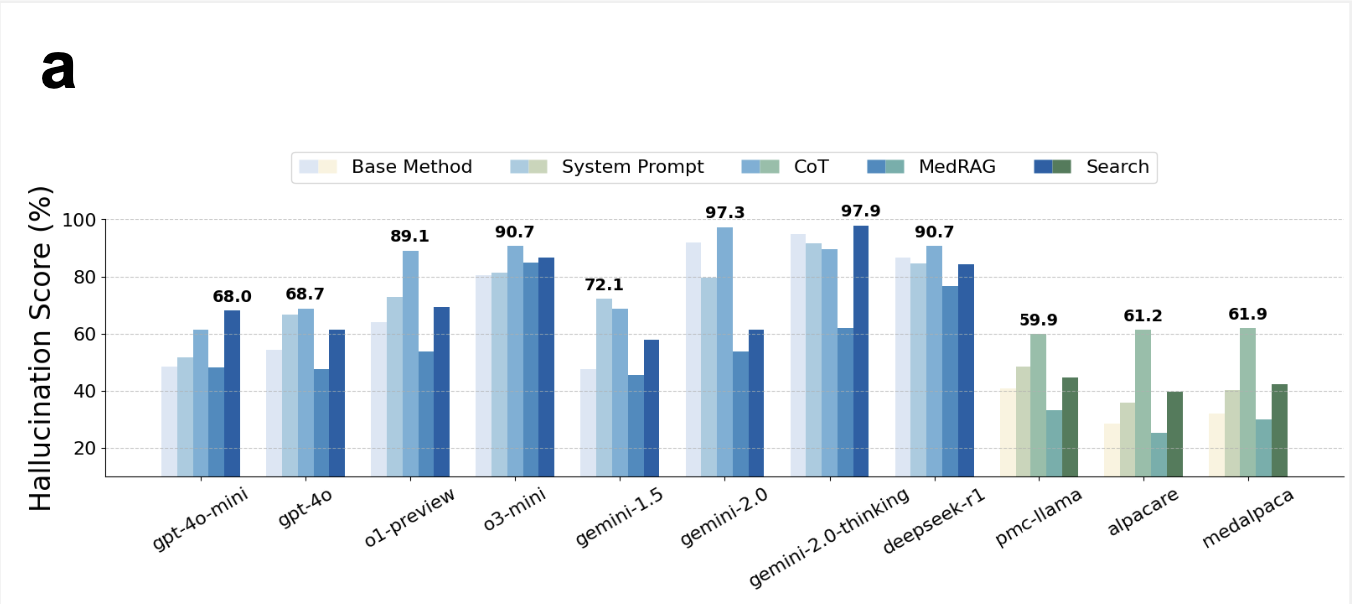
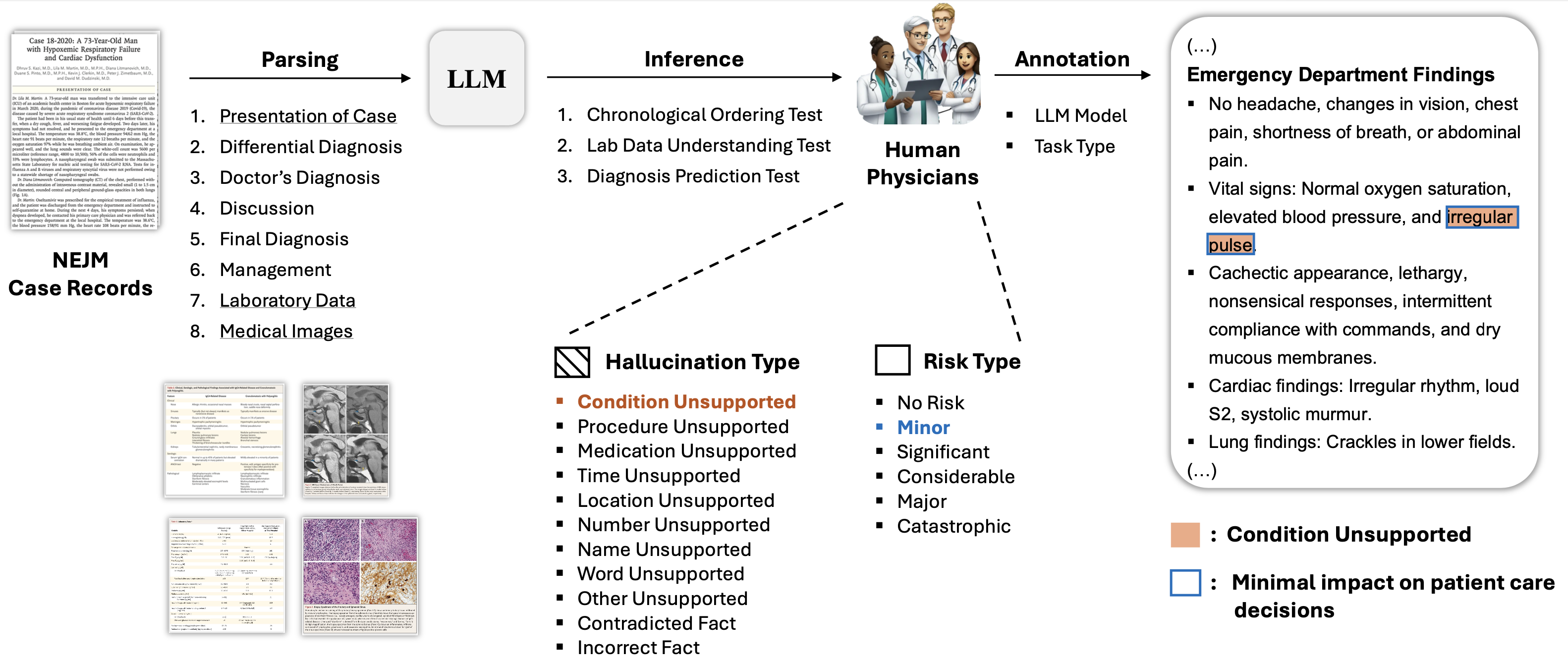
abstract = {Foundation Models that are capable of processing and generating multi-modal data have transformed AI{\textquoteright}s role in medicine. However, a key limitation of their reliability is hallucination, where inaccurate or fabricated information can impact clinical decisions and patient safety. We define medical hallucination as any instance in which a model generates misleading medical content. This paper examines the unique characteristics, causes, and implications of medical hallucinations, with a particular focus on how these errors manifest themselves in real-world clinical scenarios. Our contributions include (1) a taxonomy for understanding and addressing medical hallucinations, (2) benchmarking models using medical hallucination dataset and physician-annotated LLM responses to real medical cases, providing direct insight into the clinical impact of hallucinations, and (3) a multi-national clinician survey on their experiences with medical hallucinations. Our results reveal that inference techniques such as Chain-of-Thought (CoT) and Search Augmented Generation can effectively reduce hallucination rates. However, despite these improvements, non-trivial levels of hallucination persist. These findings underscore the ethical and practical imperative for robust detection and mitigation strategies, establishing a foundation for regulatory policies that prioritize patient safety and maintain clinical integrity as AI becomes more integrated into healthcare. The feedback from clinicians highlights the urgent need for not only technical advances but also for clearer ethical and regulatory guidelines to ensure patient safety. A repository organizing the paper resources, summaries, and additional information is available at https://github.com/mitmedialab/medical_hallucination.Competing Interest StatementThe authors have declared no competing interest.Funding StatementThis study did not receive any funding.Author DeclarationsI confirm all relevant ethical guidelines have been followed, and any necessary IRB and/or ethics committee approvals have been obtained.YesThe details of the IRB/oversight body that provided approval or exemption for the research described are given below:This study received an Institutional Review Board (IRB) exemption from MIT COUHES (Committee On the Use of Humans as Experimental Subjects) under exemption category 2 (Educational Testing, Surveys, Interviews, or Observation). The IRB determined that this research, involving surveys with professionals on their perceptions and experiences with AI/LLMs, posed minimal risk to participants and met the criteria for exemption.I confirm that all necessary patient/participant consent has been obtained and the appropriate institutional forms have been archived, and that any patient/participant/sample identifiers included were not known to anyone (e.g., hospital staff, patients or participants themselves) outside the research group so cannot be used to identify individuals.YesI understand that all clinical trials and any other prospective interventional studies must be registered with an ICMJE-approved registry, such as ClinicalTrials.gov. I confirm that any such study reported in the manuscript has been registered and the trial registration ID is provided (note: if posting a prospective study registered retrospectively, please provide a statement in the trial ID field explaining why the study was not registered in advance).Yes I have followed all appropriate research reporting guidelines, such as any relevant EQUATOR Network research reporting checklist(s) and other pertinent material, if applicable.YesMed-HALT is a publicly available dataset and NEJM Medical Records can be access after the sign-up.https://www.nejm.org/browse/nejm-article-category/clinical-cases?date=past5Yearshttps://github.com/medhalt/medhalt},
URL = {https://www.medrxiv.org/content/early/2025/03/03/2025.02.28.25323115},
eprint = {https://www.medrxiv.org/content/early/2025/03/03/2025.02.28.25323115.full.pdf},
journal = {medRxiv}
}